cylc-admin
Proposal (Accepted and Implemented): Cylc 8 Spawn-on-Demand
Hilary Oliver, December 2019, and February/March 2020
Implementation PR merged July 2020 cylc-flow#3515
Table of Contents
- Introduction
- Implementation summary
- Implementation details
- Reflow
- CLI implications
- Web UI implications
- Appendices
Introduction
Implementation PR cylc-flow#3515.
See below for terminology.
Background
We first considered replacing task-cycle-based Spawn-On-Submit (SoS) with graph-based Spawn-On-Demand (SoD) in cylc/cylc-flow#993. The ultimate solution might be cylc/cylc-flow#3304 but that requires major Cylc 9 refactoring. It turns out we can implement SoD by itself within the current system just by getting task defs (during graph parsing) to record who depends on each output, so that task proxies can spawn downstream children as outputs are completed - still a self-evolving pool of task proxies with no graph computation at run time.
Advantages
- A dramatically smaller task pool; size independent of spread over cycle points
- real task pool size limiting without risk of stall: the SoD task pool only contains active tasks, so the global queue limits task pool size
- No dynamic dependency matching (parents updates child prerequisites directly)
- No (or much less, at least) iteration over the task pool
- An easily-understood graph-based “window on the workflow”
- Users should not have to know about the “task pool” and the concepts of task “insert” and “remove” anymore.
- Task instances can run out of cycle point order
- no stalling due to unspawned tasks downstream of a failure
- No need for suicide triggers in alternate path branching
- No need to manually insert the first instance of a newly-defined task (unless perhaps it has no parents)
- Achieve ongoing “reflow” by simply re-triggering a task
Implementation summary
At start-up:
- auto-spawn first instances of parentless tasks (i.e. with no prerequisites)
Then, as outputs get completed:
- spawn downstream tasks on demand if not already spawned, and update their prerequisites directly
- as parentless tasks are released from the runahead pool, auto-spawn their next instances
- remove finished tasks (succeeded, handled-failed, expired); leave unhandled failed tasks in the pool as unfinished
- shut down if stalled with no unfinished tasks present
Implementation details
Spawn-on-outputs or spawn-when-ready?
If a task depends on the outputs of multiple parents (AND trigger) there will be a period when it has partially satisfied prerequisites, because the outputs will not all be completed at the same time (in fact the parents might not even pass through the task pool at the same time). That being the case, when exactly does SoD “demand” that we spawn the task? The options are:
- spawn the task as waiting when the first upstream output is completed, and then have it track its own prerequisites until ready (spawn on outputs), or
- start tracking the task’s prerequisites internally when the first upstream output is completed, and spawn it as ready only when the prererequisites are satisfied (spawn when ready)
Spawn-on-outputs was easiest to implement first because it leverages our task proxies’ existing ability to manage their own prerequisites. This generates some waiting tasks that might seem to create other problems, but a bit of thought shows there is actually no fundamental difference between spawn-on-outputs and spawn-when-ready. They are just slightly different ways of doing exactly the same thing, which is to manage partially satisfied prerequisites. To see this, note that we could effectively implement spawn-when-ready by spawning waiting task proxies on outputs but keeping them in a hidden pool until satisfied. Even in the main pool they don’t have to affect the workflow any differently than separately-managed prerequisites (e.g. if ignored during runahead computation they won’t stall the workflow). It should not make any difference to users either, whether or not a yet-to-run task is backed by a waiting task proxy or is just an abstract task with real prerequisite data attached to it. Housekeeping is the same too: we either remove satisfied prerequisites to avoid a memory leak, or remove spent task proxies that contain the same satisfied prerequisites.
However, we should change later to spawn-when-ready with separate management of
prerequisites, just because it’s cleaner and slightly more efficient (no excess
task proxy baggage, just the prerequisites) and doesn’t invite confusion about
the implications of waiting task proxies. The scheduler could (e.g.) maintain a
dict of (task-id, [prerequisites]): create a new entry when the first parent
output of task-id is completed, update it with subsequent outputs, and delete
it when the prerequisites are satisfied and the task can run. The dict would
also have to be stored in the DB for restarts.
For completeness, see also can we use the database or datastore to satisfy prerequisites?
UPDATE: DONE cylc/cylc-flow#3823 (Current implementation just keeps partially satisfied task proxies in the runahead pool until satisfied).
Preventing conditional reflow
If a task depends conditionally on the outputs of multiple parents (OR trigger), we need to stop the task being spawned separately by each parent ouput (because the outputs will not all be completed at the same time, and in fact the parents may not even pass through the pool at the same time).
A | B => C
Here, if C triggers off of A first, we need to stop it spawning again when
B completes later on. We can’t rely on the existence of C in the task pool
to stop this because C could be finished and gone before B completes.
We can prevent this “conditional reflow” very simply, by spawning only if the database says the task was not previously spawned in this flow. This requires an extra DB query for every late output in a conditional trigger (where late means the downstream task has finished and gone before the next parent output is generated). It has no impact on AND triggers where the task will remain in the pool until it runs, and a spawn-time DB query is needed to get submit number anyway.
It seems unlikely this extra DB access will be a problem, but see possible in-memory prevention of conditional reflow.
Prerequisite housekeeping?
The minimum housekeeping requirement is to delete partially satisified prerequisites once satisfied (or for spawn-on-outputs, reset the waiting tasks that contain those prerequisites, to ready) then remove task proxies once finished.
The more interesting question is: can prerequisites get stuck forever as partially satisfied (or stuck waiting tasks for spawn-on-outputs), and if so what should we do about that?
Note this is not a SoD-specific problem. It is even worse in SoS where have to worry about tasks gettings stuck wholly unsatisfied as well. There we force users to clean them all up with suicide triggers, or else let them stall the workflow.
We have provisionally decided not to attempt automatic removal of stuck prerequisites on grounds that partial completion of the requirements for a task to run probably means something is wrong that the user needs to know about. It can only happen if some of the associated outputs were generated while others were not. That could mean:
- a parent did not show up
- (workflow not stalled) maybe we just haven’t waited long enough yet
- (workflow stalled) just a secondary symptom of an upstream problem
- a parent succeeded without generating an expected output
- an error that needs attention
- a parent failed unhandled
- we consider the parent unfinished and leave it for the user to fix-and-retrigger, which would also allow the child to run
- a parent failed handled and was removed as finished
- bad failure handling that did not fix the workflow or clean up?
If any of the above do prove problematic we could leave this as a remaining niche case for suicide triggers, or consider possible stuck-prerequisite housekeeping.
Note that reflow can also generate tasks that are stuck waiting on off-flow outputs, but these should not be removed.
Spawning parentless tasks
Tasks with no prerequisites (or which only depend on clock or external triggers) need to be auto-spawned, because they have no parents to “demand” them. At start-up we auto-spawn the first instances of these tasks, then whenever one is released from the runahead pool, spawn its next instance.
(In future, we may want to spawn tasks “on demand” in response to external trigger events too, but for now a waiting task with an xtrigger is fine).
Absolute dependence
At first glance this is not a great fit for the spawn-on-demand model:
...
R1/2 = "start"
P1 = "start[2] => bar"
Above, with no final cycle point a single event (start.2 succeeded) should
spawn an infinite number of children (bar.1,2,3,...), which obviously is not
feasible.
(Note without the first line above start is not defined on any sequence, so
with SoS the scheduler will stall with bar unsatisfied, but with SoD it will
shut down immediately with nothing to do because bar never gets spawned.)
Worse, bar could also have other non-absolute triggers, and it could be
those that spawn initial instances of bar before start is finished:
...
R1/2 = "start"
P1 = "start[2] & foo => bar"
Above, if foo runs 3x (say) faster than start then roughly speaking the
first three instances of foo will spawn the first three instances of bar
before start.2 is done. This suggests we might need to do repeated checking
of unsatisfied absolute triggers until they become satisfied. However, it turns
out that’s not necessary…
Absolute trigger implementation:
- Whenever an absolute output (e.g.
start.2:succeedabove) is completed the scheduler should:- Remember it forever, via a list held by the task pool module and an associated DB table (to load the data again on restart).
- Spawn (if not already spawned) the first downstream child (
bar.1above) and update the prerequisites of potentially multiple subsequent children already in the pool due to spawning by others (e.g.fooabove).
- Whenever a task with an absolute trigger (
barabove) is spawned, check to see if the trigger is already satisfied. If it is, satisfy it. If it isn’t then it will be satisfied later when the absolute parent finishes and updates all child instances present in the pool as described just above. - Whenever a task with an absolute trigger is released from the runahead pool spawn its next instance (strictly speaking this is only necessary for tasks with no non-absolute triggers to spawn them on demand).
Retriggering
Retriggering a finished absolute parent (with --reflow) causes it to spawn
its first child, and subsequent instances of the parent will also continue to
be spawned as they drop out of the runahead pool as described above.
- TODO should we always auto-spawn these tasks in a reflow?
- TODO specify a new first child on retriggering an absolute parent?
Failed task handling
We have provisionally decided to remove failed tasks immediately as finished if
handled by a :fail trigger, but otherwise leave them in the pool as
unfinished, in anticipation of user intervention.
However we may want to reconsider this later; see better failed task handling?
Workflow stop
If the workflow stalls, that means there is nothing else to do (given the graph and what transpired at run time)
- if there are failed or waiting tasks in the pool, log this as a stall and stay up
- otherwise shut down as completed
This works fine but I think we could do better - see better workflow completion handling.
UPDATE: DONE cylc/cylc-flow#3823
Task pool content at shutdown
With a stop point prior to the final cycle point (stop now etc.) the scheduler will stop with waiting tasks in the runahead pool beyond the stop point. This allows a restart to carry on as normal, beyond the stop point.
The task pool will be empty on stopping at the final cycle point because that represents the end of the graph where all recurrence expressions end. It is not possible to restart from here. To go beyond the final cycle point you need to change the final cycle point in the workflow definition and restart from an earlier checkpoint, or warm start prior to the new final point.
Suicide triggers
Suicide triggers are no longer needed for workflow branching because waiting tasks do not get spawned on the “other” branch. Below, if A succeeds only C gets spawned, and if A fails only B gets spawned:
A:fail => B
A => C
Tim W’s case: B triggers and determines that xtrigger1 can never be
satisfied, so we need to remove the waiting A (the two xtriggers are watching
two mutually exclusive data directories for a new file):
@xtrigger1 => A
@xtrigger2 => B
As described this remains a case for suicide triggers (although they won’t be needed here either if we can spawn xtriggered-tasks “on demand” too, in response to xtrigger outputs).
We will keep suicide triggers for backward compatibility, and in case they are still useful for rare edge cases like this.
Suicide trigger implementation
Suicide triggers are just like normal triggers except for what happens once they are satisfied (i.e. the task gets removed instead of submitting). In particular, the suicide-triggered task has to keep track of its own prerequisites so it knows when it can be removed.
foo & bar => baz
Above, if foo (say) succeeds before bar, then baz will be
spawned (if not already spawned elsewhere) by foo:succeed and its
prerequisites updated, before later being updated again by bar:succeed, and
then it can run.
Simliarly for suicide triggers:
foo & bar => !baz
Here, if foo (say) succeeds before bar, then baz will be spawned (if not
already spawned elsewhere) by foo:succeed and its prerequisites updated,
before later being updated again by bar:succeed, and then it can be
removed.
Normally in the case of suicide triggers baz will already have been spawned
earlier, so both foo and bar will just update its prerequisites and log
a message about not spawning it again in this flow, and it will be removed once
both are done. If it was spawned earlier but removed as finished, then only the
messages will be logged (in this case baz doesn’t need to track its own
prerequisites and remove itself once they are satisfied, because it has already
been removed).
Submit number
Submit number should increment linearly with any re-submission, automatic retry or forced retriggering.
In SoS retriggering a finished task that is still in the pool just increments the in-memory submit number. Otherwise submit number gets looked up in the DB, but this is broken: re-inserted tasks get the right submit number from the DB, but their spawned next-cycle successors start at submit number 1 again.
In SoD we have the additional complications that finished tasks don’t stay in the pool, and reflows can be triggered over the top of an earlier flow. We can’t assume that submit number always starts at 1 in the original flow because it is possible to trigger a “reflow” out the front of the main flow. The only foolproof method to always get the right submit number (and thus never clobber older job logs) is to look it up in the DB whenever a new task is spawned. As it turns out the same DB query can also determine associated flow labels (next).
Reflow
Reflow means having the workflow continue to “flow on” according to the graph from a manually re-triggered task.
Reflow in SoS
A restricted form of reflow occurs automatically in SoS if you (re-)insert
and trigger a task with only previous-instance dependence (foo[-P1] => foo).
Otherwise it requires laborious manual insertion of downstream task proxies and/or state reset of existing ones to set up the reflow.
Reflow in SoD
Reflow naturally happens in SoD. Consider the cycling workflow graph:
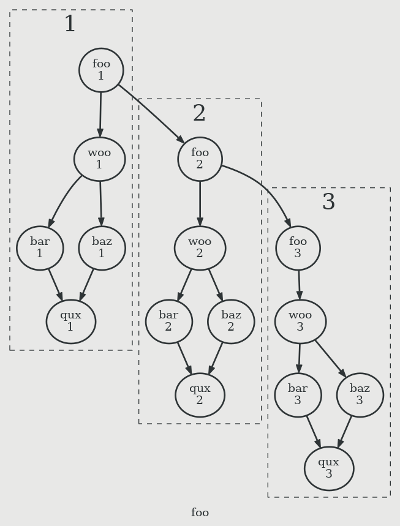
Retriggering a finite sub-graph from a bottleneck task is straightforward and safe:
- Trigger
woo.2, thenbar.2,baz.2, andqux.2will follow, and the reflow will stop.
Retriggering an ongoing cycling workflow from a bottleneck task is equally straightforward:
- Trigger
foo.2, then the workflow will carry on from that point just like the original flow
Retrigging a non-bottleneck task will cause a stalled reflow without manual intervention, because previous-flow outputs are not automatically available
- Triggering
baz.2will result in an waitingqux.2with an unsatisfied dependence onbar.2 - But the intervention to deal with this is straightforward and consistent:
- Tell Cylc to spawn the child of
bar.2:succeeded(before triggeringbaz.2to set up an automatic reflow, or after to unstall it) - OR trigger
qux.2afterbaz.2finishes, to make it run despite its unsatisfied prerequisite
- Tell Cylc to spawn the child of
Conditional reflow prevention must be flow-specific. In A | B => C if C
spawns off of A in flow-1, we should not spawn another C off of B in
flow-1, but we should spawn another C if flow-2 hits the trigger later on.
Flow labels and merging
To distinguish different flows, tasks associated with the same flow have a common flow label that is transmitted downstream to spawned children.
Users should probably be advised to avoid running multiple flows in the same part of the graph at the same time, unless they know what they’re doing, because that would likely involve multiple sets of identical or near-identical jobs running at nearly the same time, which would likely be pointless. However, the system should ensure that nothing pathological happens if one flow does run into another.
We could make flows independent (able to pass through each other unimpeded) but that just seems like a perverse way of running multiple instances of the same workflow at once.
Instead, if one flow catches up to another, they should merge together. The only way to achieve this, realistically, is to merge flow labels wherever a task from one flow encounters the same task from another flow already present in the task pool. So flows merge gradually, not all at once. When this happens the task will take forward a new merged flow label that can act as either of the original flows downstream.
Flow labels are currently implemented as a random character chosen from the set
[a-zA-Z], with merged labels represented by joining the upstream labels. So
if flow “a” catches up with flow “U”, the merged flow will be labelled “aU” and
will act as if it belongs to “a”, “U”, or “aU”. This allows for 52 concurrent
flows, which should be plenty, but is super easy to read and type (c.f.
verbose UUIDs merging to a list of UUIDs).
There’s no need to keep track of which is the original flow, it doesn’t matter.
We should periodically and infrequently (main loop plugin) remove flow labels that are common to the entire task pool. If flows ‘a’ and ‘U’ merge, eventually all labels will contain ‘aU’ (and some may carry additional labels as well from more recent triggering). At that point we might as well replace ‘aU’ with a single character label.
Reflow restrictions
- Don’t reflow by default, just trigger (require
cylc trigger --reflow) - Stop a labeled flow: stops tasks with a sole label match from spawning, and removes the label from tasks with multiple (merged) labels
CLI implications
-
cylc insertnot needed. In SoD just trigger a task - auto insertion is needed because there aren’t any waiting or finished tasks hanging around to be triggered. cylc spawnis repurposed to spawn downstream on specified outputs.- now renamed to
cylc set-outputs
- now renamed to
-
cylc removenot needed? In SoS removing a task instance from the pool removes the abstract task entirely from the workflow, if the next instance isn’t spawned first. In SoD removing active tasks doesn’t make sense (the job is already active) and will not stop future instances being spawned on demand. We can keep the it temporarily for removal of stuck waiting tasks, until we go to spawn-when-ready. -
cylc resetnot needed. In SoS this forces the state of task instances in the pool to change, to change the result of subsequent dependency negotiation (to get a task to run) e.g. to lie that a failed task succeeded. SoD does not have non-active tasks or dependency negotiation. Abstract tasks out front are already “waiting” and don’t need to be in the task pool. Finished tasks are removed immediately. Failed tasks are just historical information and pretending they succeeded is unnecessary - better force downstream tasks to carry on despite the upstream failure (withcylc spawn, above). cylc reflow- tentative new command for managing reflows, so far just supports canceling a reflow.
CLI task globbing:
In SoS we glob on:
- name and cycle point to match instances in the task pool:
spawn,poll,kill,remove,reset,trigger
- name only, for a given cycle point, to match abstract tasks:
insert
In SoD we need to glob on:
- name and cycle point to match active tasks in the task pool:
poll,kill
- name only, for a given cycle point, to match abstract tasks:
spawn,trigger
- actually trigger needs both kinds of globbing: we might still want to re-trigger multiple unhandled failed tasks at once (i.e. match in the task pool) for instance.
Web UI implications
Primarily:
- n>0 windowing:
- UIS needs to populate n>0 abstract tasks with historical data
- Probably only allow n=1 (next task) in the future direction
Approaching a stop point:
- If the workflow is told to shut down before the final cycle point (i.e. before the end of the graph) there may be some waiting tasks held back in the runahead pool because they are beyond the stop point even though they have all prerequisites satisfied. TODO: do we need the UI to make this clear? Probably not (other than making the approaching scheduler stop point clear) - it isn’t really any different from waiting satisfied tasks held back because they are beyond the runahead limit.
Graph isolates: expanding the n-distance window will not reveal tasks that are not connected (via the graph) to n=0 tasks (nasty example: cycling workflows with no inter-cycle dependencies).How should the UI make these easily discoverable?
- Provide and “n-max” window that includes whole cycle points?
- Or is searching or filtering by name sufficient?
Reflow:
- Need to distinguish between reflow and main-flow in the UI so that it is clear to users why a task with off-reflow dependence is stuck waiting (off-reflow parents will appear as finished if the window is expanded). Simply distinguishing reflow from main flow should be sufficient because it will be relatively easy to explain the problem to users (compared to SoS)
- Allow selecting part of the graph, or particular tasks, to define the bounds of a reflow?
Task Outputs:
- The SoD analogue of “task state reset” in SoS, is to tell a task to spawn
graph-children of particular outputs. E.g. If a task failed but we want to
the workflow to carry on as if it succeeded, in SoS we would reset the failed
to succeeded and dependency matching would result in triggering of downstream
tasks that depend on its success. Changing a failed task to succeeded isn’t
ideal because it hides the fact that it actually succeeded, but at least the
change to succeeded is obvious to users. For SoD we would leave the task as
failed (changing its state to succeeded wouldn’t have any effect) but tell it
to spawn based on the
:succeededoutput even though it failed. This is more elegant, but we need to make what happened obvious to users by getting the UI to display the state of individual outputs (in the workshop we considered UI design for custom outputs - can use the same for standard outputs?)
Appendices
Possible in-memory conditional reflow prevention
(For comparision with DB-based conditional reflow prevention above.
This would involve remembering that a task was previously spawned until all of its parents are finished - at which there are no parents left to cause the problem.
My initial implementation involved keeping finished task proxies in the pool until their parents were finished, but that required spawning on completion as well as on outputs, and task proxies can only hold the finished status of all their parents if spawned on completion as well as on outputs (e.g. to catch parents that finished by failure instead of success). This was a departure from the SoD concept, and it created extra (non on-demand) waiting tasks that also required parents-finished housekeeping. Too complicated.
A simpler in-memory solution is feasible though: maintain (e.g.) a dict of
(spawned-task-id, [list of unfinished parents]). Create a new entry when the
first parent finishes, and update it on subsequent parent completions. Remove
the entry once the list of unfinished parents is empty. This dict would also
have to be stored in the DB for restarts. Some tricky housekeeping might be
needed though: what to do with dict entries that get “stuck” because one or
more parents never run at all. That could happen after upstream failures, in
which case fixing the failure might fix the problem, but it could also happen
when the parent tasks are on different alternate paths.
Can we use the datastore instead of the DB?: parents are one edge from children, so if we keep n=1 tasks in the scheduler datastore, can we use that to see if the child was spawned already? Kind of: the child can drop out of n=1 if there is a gap between parents running, in which case it has to be loaded into n=1 again from the DB when the next parent shows up. So this avoids the in-memory housekeeping problem but only by secretly using the DB as long term memory. Plus, we want to keep only n=0 in the scheduler datastore if possible.
Can we use the database or datastore to satisfy prerequisites?
We’ve chosen in-memory management of partially satisfied prerequisites above, but for completeness here are two other possible solutions.
Pure DB: when an output is completed we could try to satisfy the prerequisites of the downstream task using the DB. This would involve looking up all of the other contributing parent outputs each time. If the prerequisites are completely satisfied, spawn the task, otherwise don’t. This would avoid any need for prerequisite housekeeping, but at the cost of a lot more DB access for tasks with many parents.
Can we use the datastore to satisfy prerequisites? Prerequisites are n=1 edges, so could we keep n=1 in the scheduler datastore and use that to check prerequisites before spawning? The answer is no because the as-yet-unspawned child task is n=1 from the parent that just generated the output, but all the other parents have to be checked as well to resolve its prerequisites, and they are n=2 from the original parent. So what about keeping n=2 in the datastore? Kind of: we can check all parents at n=2 whenever an output is generated, but parents don’t have to run concurrently so they can drop out of n=2 between one parent running and the next, in which case they would have to be loaded into n=2 from the DB again when the next parent shows up. So this would work, but with back-door use of the DB as long term memory. Plus we want to keep only n=0 in the scheduler datastore if possible.
Possible stuck-prerequisite housekeeping
We have provisionally decided not do to automatic housekeeping of stuck prerequisites - see above.
If we change our minds about this, we could potentially remove partially satisfied prerequisites (spawn-on-ready) or waiting tasks (spawn-on-outputs) if their parent tasks are all finished, and perhaps also if the rest of the workflow has moved on beyond them, because at that point nothing could satisfy them automatically.
Stuck prerequisites are not an immediate problem, it only matters if they accumulate over time. We don’t have to let them stall the workflow either (although they are often the result of a failure that causes it to stall). So housekeeping could be done by checking the status of the relevant parent tasks via the DB at stall time, or perhaps by infrequent periodic main loop plugin.
Better failed task handling?
We currently remove failed tasks as finished if handled by a :fail trigger,
but otherwise leave them in the pool as unfinished, in anticipation of user
intervention.
However it would be simpler just to remove all failed tasks, and that would be fine because:
- the scheduler does not need failed tasks in the pool to do its job
- ability to retrigger does not depend on continued presence in the pool (it needn’t affect reflow/no-reflow triggering either)
- it doesn’t have to impact how failed tasks are presented in the UI either
- it’s not necessarily true that failed tasks are finished if
:failis handled and not finished if not. Correct failure handling could be done by an event-handler; and we may still want to retrigger a handled failed task if the:fail-handler did not do the right thing
Handling all failed tasks equally would also make for simpler and more consistent workflow completion handling (below).
Better workflow completion handling?
UPDATE: DONE cylc/cylc-flow#3823
Completion and shutdown handling as described (above) leaves a bit to be desired.
In SoD the following workflow will complete and shut down after running only
a, i.e. it won’t be identified as a stall (it would in SoS):
graph = "a:out1 => bar"
[runtime]
[[a]]
script = true
That’s the correct thing to do according to the graph. If a does not generate
the out1 output, there is no path to bar, and the workflow is complete.
This on the other hand:
graph = """a & b => bar
# and optionally:
b:fail => whatever"""
[runtime]
[[a]]
script = true
[[b]]
script = false
… will be identified as a stall, even though there is no path to bar here
either. There will be a partially satisfied (waiting) bar, and (depending
on how we handle failed tasks) a failed b in the pool.
That seems inconsistent. In fact there’s really no need to make potentially-incorrect value judgements about the meaning of partially satisfied prerequisites, handled or unhandled failed tasks, or stall vs completion. An unexpected failure might cause the worklfow to stall by taking a side path, but it is impossible for us to know what the “intended” path is (who are we to say that the supposed side path was not actually the intended path?)
Instead (simple!):
- If the workflow stalls for any reason, there is by definition nothing else to
do, so just say that and shut down (possibly after a timeout to allow quick
intervention).
- If there are partially satisfied prerequisites present, by all means log them, but that does not necessarily imply a premature stall (see example above)
- The user can then look at what led to the stall, if necessary intervene to make the workflow continue on again, on a different path
Aside on current flawed SoS completion logic: tasks are spawned ahead as waiting regardless of what is “demanded” by the graph at run time, but the workflow still proceeds “on demand”. If the scheduler stalls with waiting tasks present we infer a premature stall, but that might not be a valid conclusion. The scheduler got to this point by doing exactly what the graph said to do under the circumstances that transpired, and who are we to say that the user did not intend that? But unfortunately in SoS we may end up with a bunch of off-piste waiting tasks to deal with, and we use those to infer an intention to follow a different path.
UPDATE: DONE cylc/cylc-flow#3823
Automatic use of off-flow outputs?
This is possible in principle but we have decided against it as difficult and dangerous. Also, it is really not necessary. SoD reflow is a big improvement even without this (less intervention, straightfoward and consistent).
(Note we actually have a similar-but-worse problem in SoS: previous-flow task outputs will not be used automatically unless those tasks happen to still be present in the task pool - and users do not generally understand what determines whether or not those tasks will still be present).
(For the record, in case we ever reconsider automatic use of off-reflow outputs, graph traversal would be required to determine whether or not an unsatisfied prerequisite can be satisfied later within the reflow or not, and if not, to go the database. As Oliver noted: this could probably be worked out once at the start of the reflow; it could also help us show users graphically the consequences of their intended reflow).
TODO
The following have been transferred to sod-follow-up Issues in cylc-flow
- (DM) Do we need to support reflow without continued spawning of parentless or
absolute-parented tasks? Example:
R1 = start P1 = start[^] => foo => bar & baz => quxIf I retrigger
foo.6with--reflowit should causebar.6andbaz.6thenqux.6to run, but it will also result infoo.7being spawned and so on - is that to be expected or not? (Note we an already get restricted child-only reflow by triggeringfoo.6without reflow, and thencylc spawn foo.6[nowcylc set-outputs] to spawn the children offoo.6). -
Consider allowing users to specify the first child to be spawned by a retriggered absolute parent rather than going back to the first cycle (use case: retrigger a start-up task that rebuilds a model but does not re-run all the old cycles that depend on the model build, just new ones; alternatively, just retrigger the absolute parent without reflow, then retrigger (with reflow) the first child that you want the children to continue from).
-
Consider the clarity and usefulness of all SoD log messages. Messages about not spawning suicide-triggered tasks have been noted as confusing. Move most to DEBUG level?
-
Don’t auto-spawn all tasks with an absolute trigger, just those that only have absolute triggers (auto-spawning them all isn’t really a problem, but it is less “on demand” than it could be).
- Event-driven triggering: easy (see TODO at the end of
task_pool:spawn_on_ouput) but need to consider the effect on batched job submission.- UPDATE: DONE cylc/cylc-flow#3898
-
Consider re-instating (most of?) the pre-SoD
cylc insertfunctional tests ascylc triggertests. - “Hold” currently means to hold back waiting task proxies. In SoD we can
still hold a suite, but holding individual tasks is impossible except for
partially satisfied waiting tasks.
- Do we really need the concept of individual task hold? If we do, options include:
- (maybe) holding an active task causes its spawned children to be held?
- (probably) allow users to target any task, which will require the scheduler to check a list of tasks-to-hold at spawn time
-
Consider if current flow label management is sufficient, and allow users to associate metadata with flow labels so they can keep track more easily.
- Flow stop is currently implemented as
cylc stop --flow=LABEL. Consider better integrating this other stop functionality; and also hold etc. From Oliver:Consider a way to pull flow name into the generic identification system in the guise of:
$ cylc hold <workflow> <cylc> $ cylc hold <workflow> <task>.<cycle> $ cylc hold <workflow> <task>.<cycle>^<flow> $ cylc hold <workflow> ^<flow> -
Event-driven removal of finished tasks is not compatible with the way the datastore is updated by iterating the task pool once per main loop (so we miss final status changes).
- Generally ensure that users do not need to understand the “task pool”
anymore, beyond the distinction between active and not-active tasks.
- e.g. no more glob-matching of the task pool on task state (
cylc triggeralready converted over to targetting any task) - the result of retriggering should be the same regardless of whether or not the target task is already in the pool. This could matter for handled (not in pool) vs unhandled failed (in pool) tasks - which I’m suggesting we treat equally and remove them all; and partially-satisfied (in pool) vs wholly unsatisfied (not) waiting tasks - but note the former should really only be treated as embodied prerequisites - see spawn-on-outputs or spawn-when-ready?.
- e.g. no more glob-matching of the task pool on task state (
-
The retrigger vs reflow distinction is clear when the target task is well in front of or behind the original flow, but what about retriggering a failed task? Presumably that should result in the original flow continuing (if the retriggered task succeeds and satisfies downstream prerequisites) even if the user did not use
cylc trigger --reflow? -
Other ways of stopping a reflow? (at a cycle point, or at a list of task IDs?)
-
(Edit-run has been removed, but that needs to be re-implemented via UI + UIS)
- In storing satisfied prerequisite status in the DB task pool table, OS is not
happy that “the keys to a JSON dictionary are themselves JSON” and suggests
“This should be converted into its own DB table pre-8.0.0.” - search for
“satisfied” in
cylc/flow/suite_db_mgr.pyandcylc/flow/task_pool.py.- UPDATE: DONE
cylc/cylc-flow#3863
- UPDATE: DONE
-
Rethink runahead limiting. A global queue with cycle-point priority release would be better because it limits activity within a cycle point as well as across cycle points cylc/cylc-flow#3874 Note also the global queue provides real task pool size limiting without risk of stall, not just active task limiting, because the task pool only contains active tasks.
- Go to spawn-when-ready instead of spawn-on-outputs, as discussed above
- UPDATE: DONE cylc/cylc-flow#3823
-
Try to avoid all remaining iteration over task proxies
-
Can we make prerequisite updates more efficient (it uses the old dependencies matching methods)
- Extend SoD to clock- and external-triggers: tasks could be spawned in response to trigger events (depends on xtriggers as main-loop coroutines)
- (Consider all “possible” Appendix items above)
Terminology
- parent and child tasks: upstream and downstream graph relationships. (Not runtime inheritance!)
- task: an abstract node in the workflow graph (task name at a particular cycle point)
- task proxy: an object in the scheduler program representing a particular task that the scheduler is currently aware of
- task pool: pool of current “active” task proxies
- runahead pool: task proxies that have been spawned (created) already but are beyond the current runahead limit, or beyond the (non-final) stop point. All tasks are initially spawned into the runahead pool then released to the main pool as the workflow (and the runahead limit) moves forward.
- n=0 window: tasks that anchor the current view (by default, the content of the active task pool)
- n=M window: tasks within M graph edges of the those in the n=0 window
- finished: means succeeded, OR failed with the :fail trigger handled. An unhandled failed task is retained in the task pool as “not finished”
- reflow: when the workflow flows on according to the graph, from a manually triggered task