Basic Principles
This section covers general principles that should be kept in mind when writing any workflow. More advanced topics are covered later: Efficiency And Maintainability and Portable Workflows.
Cycle point time zone
Cylc has full local timezone support if needed, but the default cycle point time
zone is UTC. See flow.cylc[scheduler]cycle point time zone.
Fine Or Coarse-Grained Workflows
Workflows can have many small simple tasks, fewer large complex tasks, or anything in between. A task that runs many distinct processes can be split into many distinct tasks. The fine-grained approach is more transparent and it allows more task level concurrency and quicker failure recovery - you can rerun just what failed without repeating anything unnecessarily.
Rose Bunch
One caveat to our fine-graining advice is that submitting a large number of small tasks at once may be a problem on some platforms. If you have many similar concurrent jobs you can use rose_bunch to pack them into a single task with incremental rerun capability: retriggering the task will rerun just the component jobs that did not successfully complete earlier.
Monolithic Or Interdependent Workflows
When writing workflows from scratch you may need to decide between putting multiple loosely connected sub-workflows into a single large workflow, or constructing a more modular system of smaller workflows that depend on each other through inter-workflow triggering. Each approach has its pros and cons, depending on your requirements and preferences with respect to the complexity and manageability of the resulting system.
Self-Contained Workflows
All files generated by Cylc during a workflow run are confined to the workflow
run directory $HOME/cylc-run/<workflow-id>. However, Cylc has no
control over the locations of the programs, scripts, and files, that are
executed, read, or generated by your tasks at runtime. It is up to you to
ensure that all of this is confined to the run directory too, as far as
possible.
Self-contained workflows are more robust, easier to work with, and more portable. Multiple instances of the same workflow (with different workflow names) should be able to run concurrently under the same user account without mutual interference.
Avoiding External Files
Workflows that use external scripts, executables, and files beyond the essential system libraries and utilities are vulnerable to external changes: someone else might interfere with these files without telling you.
In some case you may need to symlink to large external files anyway, if space or copy speed is a problem, but otherwise workflows with private copies of all the files they need are more robust.
Confining Output To The Run Directory
Output files should be confined to the run directory tree. Then all
output is easy to find, multiple instances of the same workflow can run
concurrently without interference, and other users should be able to copy and
run your workflow with few modifications. Cylc provides a share
directory for generated files that are used by several tasks in a workflow
(see Shared Task IO Paths). Archiving tasks can use rose arch
to copy or move selected files to external locations as needed (see
Workflow Housekeeping).
Task Host Selection
The rose host-select command is now deprecated. Workflows should migrate
to using platforms which provide a more efficient
solution.
See Platforms for details.
Task Scripting
Non-trivial task scripting should be held in separate script files rather than
inlined in flow.cylc. This keeps the workflow definition tidy, and it
allows proper shell-mode text editing and independent testing of task scripts.
For automatic access by jobs, task-specific scripts should be kept in Rose app bin directories, and shared scripts kept in (or installed to) the workflow bin directory.
Coding Standards
When writing your own task scripts make consistent use of appropriate coding standards such as:
Basic Functionality
In consideration of future users who may not be expert on the internals of your workflow and its tasks, all task scripts should:
Print clear usage information if invoked incorrectly (and via the standard options
-h, --help).Print useful diagnostic messages in case of error. For example, if a file was not found, the error message should contain the full path to the expected location.
Always return correct shell exit status - zero for success, non-zero for failure. This is used by Cylc job wrapper code to detect success and failure and report it back to the scheduler.
In shell scripts use
set -uto abort on any reference to an undefined variable. If you really need an undefined variable to evaluate to an empty string, make it explicit:FOO=${FOO:-}.In shell scripts use
set -eto abort on any error without having to failure-check each command explicitly.In shell scripts use
set -o pipefailto abort on any error within a pipe line. Note that all commands in the pipe line will still run, it will just exit with the right most non-zero exit status.
Note
Examples and more details are available
for the above three set commands.
Inline scripts (defined in the job-script section of the
workflow configuration) do not need to set -euo pipefail:
It is already set as part of the
job script’s error handling.
Rose Apps
Rose apps allow all non-shared task configuration - which is not relevant to
workflow automation - to be moved from the workflow definition into app config
files. This makes workflows tidier and easier to understand, and it allows
rose edit to provide a unified metadata-enhanced view of the workflow
and its apps (see Rose Metadata Compliance).
Rose apps are a clear winner for tasks with complex configuration requirements.
It matters less for those with little configuration, but for consistency and to
take full advantage of rose edit it makes sense to use Rose apps
for most tasks.
When most tasks are Rose apps, set the app-run command as a root-level default, and override it for the occasional non Rose app task:
[runtime]
[[root]]
script = rose task-run -v
[[rose-app1]]
#...
[[rose-app2]]
#...
[[hello-world]] # Not a Rose app.
script = echo "Hello World"
Rose Metadata Compliance
Rose metadata drives page layout and sort order in rose edit, plus
help information, input validity checking, macros for advanced checking and app
version upgrades, and more.
To ensure the workflow and its constituent applications are being run as intended
it should be valid against any provided metadata: launch the
rose edit GUI or run rose macro --validate on the
command line to highlight any errors, and correct them prior to use. If errors
are flagged incorrectly you should endeavour to fix the metadata.
When writing a new workflow or application, consider creating metadata to facilitate ease of use by others.
Task Independence
Essential dependencies must be encoded in the workflow graph, but tasks should not rely unnecessarily on the action of other tasks. For example, tasks should create their own output directories if they don’t already exist, even if they would normally be created by an earlier task in the workflow. This makes it is easier to run tasks alone during development and testing.
Clock-Triggered Tasks
Tasks that wait on real time data should use clock triggers to delay job submission until the expected data arrival time:
[scheduling]
initial cycle point = now
[[xtriggers]]
# Trigger 5 min after wallclock time is equal to cycle point.
clock = wall_clock(offset=PT5M)
[[graph]]
T00 = @clock => get-data => process-data
Clock-triggered tasks typically have to handle late data arrival. Task
execution retry delays can be used to simply retrigger
the task at intervals until the data is found, but frequently retrying small
tasks is inefficient, and multiple task
failures will be logged for what is a essentially a normal condition (at least
it is normal until the data is really late).
Rather than using task execution retry delays to repeatedly trigger a task that checks for a file, it may be better to have the task itself repeatedly poll for the data (see Custom Xtrigger Functions).
Rose App File Polling
Rose apps have built-in polling functionality to check repeatedly for the
existence of files before executing the main app. See the [poll]
section in Rose app config documentation. This is a good way to implement
check-and-wait functionality in clock-triggered tasks
(Clock-Triggered Tasks), for example.
It is important to note that frequent polling may be bad for some filesystems, so be sure to configure a reasonable interval between polls.
Task Execution Time Limits
Instead of setting job wallclock limits directly in job runner
directives, use
flow.cylc[runtime][<namespace>]execution time limit.
Cylc automatically derives the correct job runner directives from this,
and it is also used to run background and at jobs via
the timeout command, and to poll tasks that haven’t reported in
finished by the configured time limit.
Restricting Workflow Activity
It may be possible for large workflows to overwhelm a job host by submitting too many jobs at once:
Large workflows that are not sufficiently limited by real time clock triggering or intercycle dependence may generate a lot of runahead (this refers to Cylc’s ability to run multiple cycles at once, restricted only by the dependencies of individual tasks).
Some workflows may have large families of tasks whose members all become ready at the same time.
These problems can be avoided with runahead limiting and internal queues, respectively.
Runahead Limiting
By default Cylc allows a maximum of five cycle points to be active at the same
time, but this value can be configured by
[scheduling]runahead limit:
[scheduling]
initial cycle point = 2020-01-01T00
# Don't allow any cycle interleaving:
runahead limit = P0
Internal Queues
Tasks can be assigned to named internal :cylc:conf`queues <[scheduling][queues]>` that limit the number of members that can be active (i.e. submitted or running) at the same time:
[scheduling]
initial cycle point = 2020-01-01T00
[[queues]]
# Allow only 2 members of BIG_JOBS to run at once:
[[[big_jobs_queue]]]
limit = 2
members = BIG_JOBS
[[graph]]
T00 = pre => BIG_JOBS
[runtime]
[[BIG_JOBS]]
[[foo, bar, baz, ...]]
inherit = BIG_JOBS
Workflow Housekeeping
Ongoing cycling workflows can generate an enormous number of output files and logs so regular housekeeping is very important. Special housekeeping tasks, typically the last tasks in each cycle, should be included to archive selected important files and then delete everything at some offset from the current cycle point.
The Rose built-in apps rose_arch and rose_prune provide an easy way to do this. They can be configured easily with file-matching patterns and cycle point offsets to perform various housekeeping operations on matched files.
Complex Jinja2 Code
The Jinja2 template processor provides general programming constructs, extensible with custom Python filters, that can be used to generate the workflow definition. This makes it possible to write flexible multi-use workflows with structure and content that varies according to various input switches. There is a cost to this flexibility however: excessive use of Jinja2 can make a workflow hard to understand and maintain. It is difficult to say exactly where to draw the line, but we recommend erring on the side of simplicity and clarity: write workflows that are easy to understand and therefore easy to modify for other purposes, rather than extremely complicated workflows that attempt do everything out of the box but are hard to maintain and modify.
Note that use of Jinja2 loops for generating tasks is now deprecated in favour of built-in parameterized tasks - see Task Parameters.
Automating Failure Recovery
Job Submission Retries
When submitting jobs to a remote host, use job submission retries to automatically resubmit tasks in the event of network outages.
Note that this is distinct from job retries for job execution failure (just below).
Job Execution Retries
Automatic retry on job execution failure is useful if you have good reason to believe that a simple retry will usually succeed. This may be the case if the job host is known to be flaky, or if the job only ever fails for one known reason that can be fixed on a retry. For example, if a model fails occasionally with a numerical instability that can be remedied with a short timestep rerun, then an automatic retry may be appropriate.
[runtime]
[[model]]
script = """
if [[ $CYLC_TASK_TRY_NUMBER > 1 ]]; then
SHORT_TIMESTEP=true
else
SHORT_TIMESTEP=false
fi
model.exe
"""
execution retry delays = 1*PT0M
Failure Recovery Workflows
For recovery from failures that require explicit diagnosis you can configure alternate graph branches. In the following example, if the model fails a diagnosis task will trigger; if it determines the cause of the failure is a known numerical instability (e.g. by parsing model job logs) it will succeed, triggering a short timestep run. Postprocessing can proceed from either the original or the short-step model run.
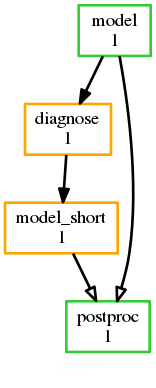
[scheduling]
[[graph]]
R1 = """
model | model_short => postproc
model:fail => diagnose => model_short
"""
Include Files
Include-files should not be overused, but they can sometimes be useful (e.g. see Portable Workflows):
#...
{% include 'inc/foo.cylc' %}
(Technically this inserts a Jinja2-rendered file template). Cylc also has a native include mechanism that pre-dates Jinja2 support and literally inlines the include-file:
#...
%include 'inc/foo.cylc'
The two methods normally produce the same result, but use the Jinja2 version if you need to construct an include-file name from a variable (because Cylc include-files get inlined before Jinja2 processing is done):
#...
{% include 'inc/' ~ SITE ~ '.cylc' %}