Efficiency And Maintainability
Efficiency (in the sense of economy of workflow definition) and maintainability go hand in hand. This section describes techniques for clean and efficient construction of complex workflows that are easy to understand, maintain, and modify.
The Task Family Hierarchy
A properly designed family hierarchy fulfils three purposes in Cylc:
efficient sharing of configuration common to groups of related tasks
efficient bulk triggering, for clear scheduling graphs
collapsible families in workflow visualization and UI views
Family Triggering
Task families can be used to simplify the scheduling graph wherever many tasks need to trigger at once:
[scheduling]
[[graph]]
R1 = pre => MODELS
[runtime]
[[MODELS]]
[[model1, model2, model3, ...]]
inherit = MODELS
To trigger off of many tasks at once, family names need to be qualified
by <state>-all or <state>-any to indicate the desired
member-triggering semantics:
[scheduling]
[[graph]]
R1 = """
pre => MODELS
MODELS:succeed-all => post
"""
Note that this can be simplified further because Cylc ignores trigger
qualifiers like :succeed-all on the right of trigger arrows
to allow chaining of dependencies:
[scheduling]
[[graph]]
R1 = pre => MODELS:succeed-all => post
Family-to-Family Triggering
[scheduling]
[[graph]]
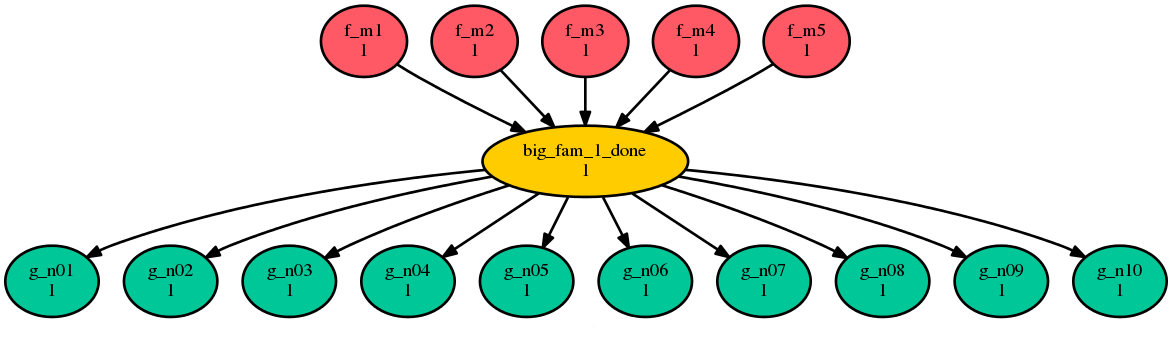
R1 = BIG_FAM_1:succeed-all => BIG_FAM_2
This means every member of BIG_FAM_2 depends on every member
of BIG_FAM_1 succeeding. For very large families this can create so
many dependencies that it affects the performance of Cylc at run time, as
well as cluttering graph visualizations with unnecessary edges. Instead,
interpose a blank task that signifies completion of the first family:
[scheduling]
[[graph]]
R1 = BIG_FAM_1:succeed-all => big_fam_1_done => BIG_FAM_2
[runtime]
[[big_fam_1_done]]
run mode = skip
For families with M and N members respectively, this
reduces the number of dependencies from M*N to M+N
without affecting the scheduling.

See also
Task Families And Visualization
First parents in the inheritance hierarchy double as collapsible summary
groups for visualization and monitoring. Tasks should generally be grouped into
visualization families that reflect their logical purpose in the workflow rather
than technical detail such as inherited job submission or host settings. So in
the example under Sharing By Inheritance above all
obs<n> tasks collapse into OBSPROC but not into
SERIAL or PARALLEL.
If necessary you can introduce new namespaces just for visualization:
[runtime]
[[MODEL]]
# (No settings here - just for visualization).
[[model1, model2]]
inherit = MODEL, HOSTX
[[model3, model4]]
inherit = MODEL, HOSTY
To stop a solo parent being used in visualization, demote it to secondary with a null parent like this:
[runtime]
[[SERIAL]]
[[foo]]
# Inherit settings from SERIAL but don't use it in visualization.
inherit = None, SERIAL
Generating Tasks Automatically
Groups of tasks that are closely related such as an ensemble of model runs or
a family of obs processing tasks, or sections of workflow that are repeated
with minor variations, can be generated automatically by iterating over
some integer range (e.g. model<n> for n = 1..10) or
list of strings (e.g. obs<type> for
type = ship, buoy, radiosonde, ...).
Jinja2 Loops
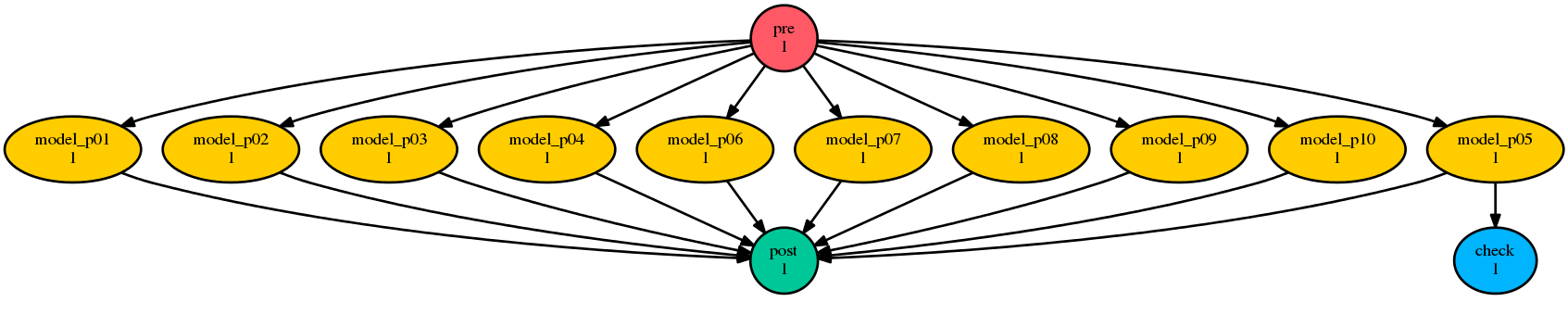
Task generation was traditionally done in Cylc with explicit Jinja2 loops, like this:
# Task generation the old way: Jinja2 loops (NO LONGER RECOMMENDED!)
{% set PARAMS = range(1,11) %}
[scheduling]
[[graph]]
R1 = """
{% for P in PARAMS %}
pre => model_p{{P}} => post
{% if P == 5 %}
model_p{{P}} => check
{% endif %}
{% endfor %} """
[runtime]
{% for P in PARAMS %}
[[model_p{{P}}]]
script = echo "my parameter value is {{P}}"
{% if P == 1 %}
# special case...
{% endif %}
{% endfor %}
Unfortunately this makes a mess of the workflow definition, particularly the scheduling graph, and it gets worse with nested loops over multiple parameters.
Parameterized Tasks
Cylc-6.11 introduced built-in workflow parameters for generating tasks without destroying the clarity of the base workflow definition. Here’s the same example using workflow parameters instead of Jinja2 loops:
# Task generation the new way: workflow parameters.
[scheduler]
[[parameters]]
p = 1..10
[scheduling]
[[graph]]
R1 = """
pre => model<p> => post
model<p=5> => check
"""
[runtime]
[[pre, post, check]]
[[model<p>]]
script = echo "my parameter value is ${CYLC_TASK_PARAM_p}"
[[model<p=7>]]
# special case ...
Here model<p> expands to model_p7 for p=7,
and so on, via the default expansion template for integer-valued parameters,
but custom templates can be defined if necessary. Parameters can also be
defined as lists of strings, and you can define dependencies between different
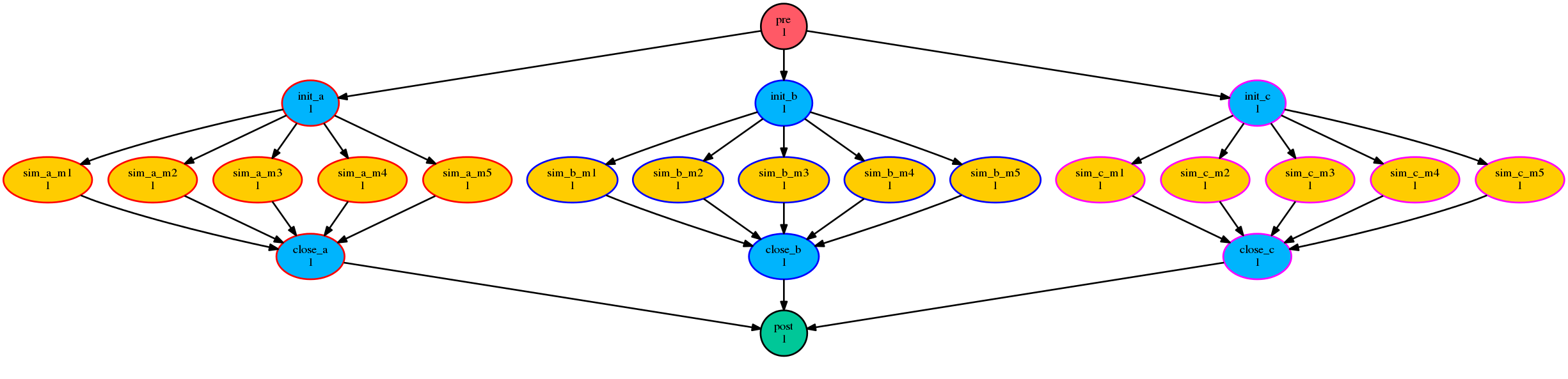
values: chunk<p-1> => chunk<p>. Here’s a multi-parameter example:
[scheduler]
allow implicit tasks = True
[[parameters]]
run = a, b, c
m = 1..5
[scheduling]
[[graph]]
R1 = pre => init<run> => sim<run,m> => close<run> => post
[runtime]
[[sim<run,m>]]
If family members are defined by workflow parameters, then parameterized
trigger expressions are equivalent to family :<state>-all triggers.
For example, this:
[scheduler]
[[parameters]]
n = 1..5
[scheduling]
[[graph]]
R1 = pre => model<n> => post
[runtime]
[[pre, post]]
[[MODELS]]
[[model<n>]]
inherit = MODELS
is equivalent to this:
[scheduler]
[[parameters]]
n = 1..5
[scheduling]
[[graph]]
R1 = pre => MODELS:succeed-all => post
[runtime]
[[pre, post]]
[[MODELS]]
[[model<n>]]
inherit = MODELS
(but future plans for family triggering may make the second case more efficient for very large families).
For more information on parameterized tasks see the Cylc user guide.
Optional App Config Files
Closely related tasks with few configuration differences between them - such as multiple UM forecast and reconfiguration apps in the same workflow - should use the same Rose app configuration with the differences supplied by optional configs, rather than duplicating the entire app for each task.
Optional app configs should be valid on top of the main app config and not dependent on the use of other optional app configs. This ensures they will work correctly with macros and can therefore be upgraded automatically.
Optional app configs can be loaded by command line switch:
rose task-run -O key1 -O key2
or by environment variable:
ROSE_APP_OPT_CONF_KEYS = key1 key2
The environment variable is generally preferred in workflows because you don’t have to repeat and override the root-level script configuration:
[runtime]
[[root]]
script = rose task-run -v
[[foo]]
[[[environment]]]
ROSE_APP_OPT_CONF_KEYS = key1 key2